Gartner predicted a few years ago that by now Serverless PaaS will reach its plateau of productivity. If you try to search which cloud providers have Serverless offering, you instantly get a feeling that we are there - in plateau. I mean besides the dominating clouds, such as AWS, Azure and GCP, there are also a large number of other neat providers and platforms like ZEIT, Kubeless, Fn Project, OpenFaaS, Cloudflare Workers and many many others.
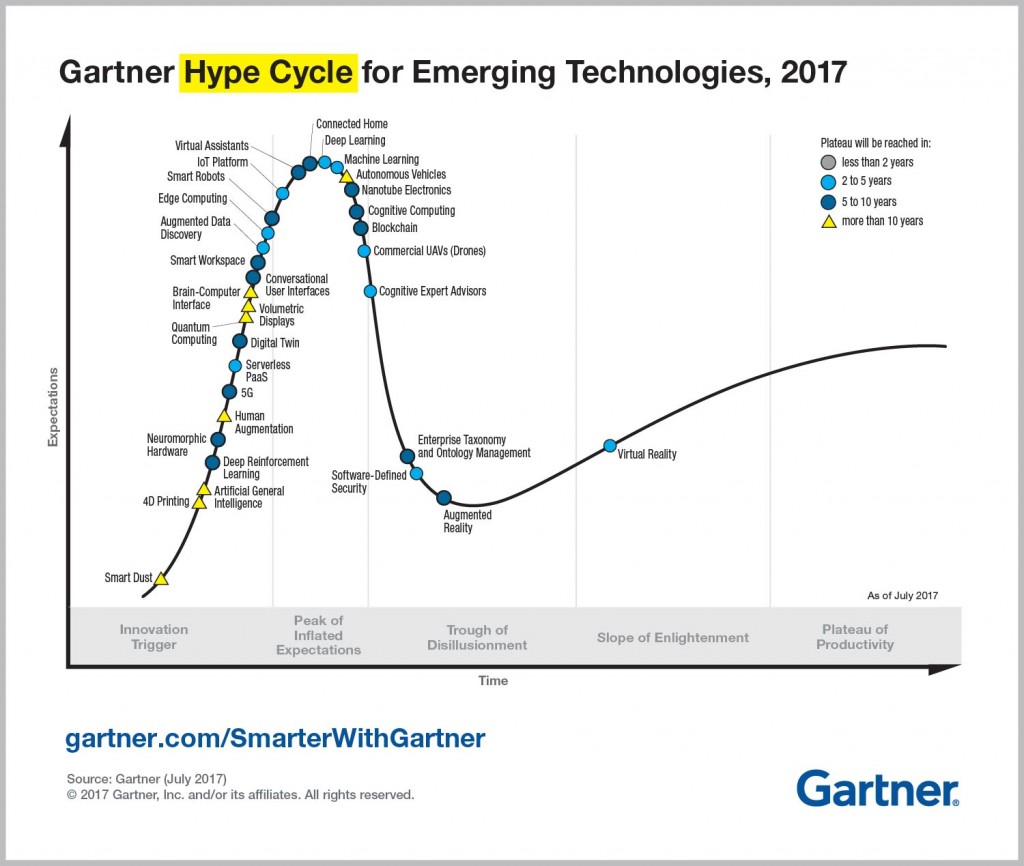
Source: The Gartner Hype Cycle for Emerging Technologies, 2017
There is also a huge amount of posts, books and videos about and how to “serverless”. You can literally drown in this amount of information without finding the essential parts.
I see many developers (including me not that along ago) either struggle with understanding which use cases it fits the best, or misuse it in such way, that it is near impossible to maintain.
My Golden Rules
While there are many guidelines that tries to cover all of the aspects of Serverless technology, I wanted to catch things that are most (or sometimes the only) things that important.
Below you will find essentials things to hold in your head while, or even before you starting, implementing application using Serverless mechanism.
Web interface trap
It is really easy to start with Serverless, while ignoring a few, or all, of the principles of software development for writing SOLID and clean code. For instance, both AWS and Azure allow to create functions directly from their web portals. Very easy to start. But man, oh man, your colleagues won’t thank you later. Maintenance, team collaboration, testing and code sharing with this approach are very challenging.
So rule #1 try to avoid creating function from the web interface, unless it is something you want to play around or you know that the lifetime of the function will be short.
Minimal work
Each function should do as minimal work as possible. This is intentionally the second rule. While in “normal” application this is obvious to all of us, in Serverless people tend to abuse a single function.
An example will be appropriate now :) Let’s say you need to call some API after a message arrives to a queue, and store the result in database. You can do it all in single function, and there might be cases when it makes sense, but I would suggest to break it apart into 3 separate functions (just like you will do in a “normal world”):
- First function triggered by a message in that queue. It will parse the message, may be filter out, may be reduce several messages into one operation. Once done, call next function (usually by placing a message to another queue).
- Next function will call 3rd party API (whether it is HTTP, RPC or something else). After it gets OK from this API, it can pass the result of the API call to the next function
- The last function will write to database the result
It is very simple - every function handles something very specific and no more than this. If you are straggling to brake a part the functionality into small peaces, it might be a sign that Serverless is not the best platform for the use case. Don’t give up quickly - there are a few tricks on how to break apart parsing huge file, processing mbillions records, paging through large datasets with continuation token, etc..
Functions should form applications
Functions should be grouped into applications (some unit of logic). Usually you won’t be writing a single, stand alone function. I mean there are exceptions, but in most cases you ended up having a set of functions which can be merged into single logical group with shared code.
This group then can reside in dedicated git repository, like a “normal” application, and deployed as a single unit, again, like a “normal” application. All platforms allows grouping functions into some sort of applications.
Once you start threating functions as applications, then it suddenly sounds obvious that they must have code reviews, CI, tests, documentation, monitoring and release management.
Idempotency
In best scenario the function should be idempotent (it is not always possible, especially when dealing with 3rd party APIs). Serverless runtimes have automatic retry policies in case function didn’t succeeded (unhandled exceptions, timeouts or out of memory). So if the function is idempotent, it will play nice with runtime - executing multiple times without creating side effects in your application.
In some cases it can helpful to use requestId/InvocationId/CorrelationId , which is supplied by a runtime on each call. If it is a retry operation, the identifier will be the same and it will allow you to detect whether the invocation already happened before.
The same correlation identifier you will find attached to log messages, which is very helpful to isolate message from one invocation to another
References:
- AWS retry policy
- Azure retry policy
- AWS
requestIdfor Node.js (similar to other languages runtimes) - Azure
InvocationId
Running time constraint
It is important to remember that there is a limit of how long the function can be running. There is a stopwatch that started once the function called, and if it reaches the limit, then your function will be terminated.
This, again, may raise the question whether the Serverless fits your use case - you cannot process a huge amount of data in single invocation, unless you measure the running time and can “pause and resume” processing.
Some platforms have an option to eliminate this limitation, but then is it still Serverless where you pay per invocation?
For instance, when dealing with huge files, think how to break it a part with offsets. If you to process a large amount of records, then probably each invocation should deal with a single or few records each time.
Bindings and triggers
IMHO this is one of the main selling points of Serverless - bindings and triggers.
Bindings is pretty unique feature in Azure
It is really allows you to concentrate on the business logic and not plumbing. Instead of hosting web server, writing queues consumer, writing poller for incoming files/records, figuring which scheduler to use, the runtime takes care for it:

It also easy to switch between triggers - you have one logic that triggered by message in queue today, and tomorrow you easily convert or add to it HTTP endpoint.
While being one of the main features, this is also one the main limitations. You end up designing the solution around the available triggers, which in some cases may be just not possible. If you need to write a consumer for Kafka in AWS Lamda, or Azure Function that triggered by new message in RabitMQ, you are out of luck. There are solutions, but they usually either involves some middle tier or polling with scheduled functions, which in my opinion kills the concept of Serverless.
Function body
The body of the function itself should not do a lot. Think of it as static void main() - you don’t write your logic there, you parse args, construct your service/s and invoke them. This way you will be also able to “unit” test your service alone, not that you always should.
There are toolings that allow you to execute functions locally (serverless, Azure Func CLI to name a few) and write a full integration tests, but I still suggest to keep function’s body clean from business logic.
Decoupling business logic from runtime environment is usually a good practice to follow. Not that it should be your guideline, but think how easily you can move your logic to non-Serverless platform (micro-service or monolith) or, may be even, other Serverless provider.
Exceptions are good
If there is something unexpected happened, you should throw exceptions as soon as possible. 3rd party API returned 429 or 503? Got transient error from db connection? Just throw - there is a retry policy in place, and eventually, after a runtime will give up on retrying it can place a message in DLQ.
If functions are small and do exactly one thing, then there is no reason to worry about exceptions being bubbled to many levels up.
If you find yourself writing or using library with complex retry with exponential backoff or something similar inside your function, ask yourself again whether the Serverless fits the use case.
Parallelism
This is also one of the main selling points of Serverless - horizontal scalability. You can control how “much of scale” you want per function. And you definitely need to be aware of it and use it, because for certain scenarios functions have insane defaults and may do you bad:
- Databases has limitation on active client connections, so you won’t be able to write in parallel with infinite amount of function instances
- If you are going to call 3rd party API at a rate of 1000 req/sec you probably will be banned
- If you are going to call your own service at this rate, it can just end up in DoS
- Crawling websites at high rate, may take them down, or if they are behind services like Cloudflare, you will be storing reCAPTCHA challenge in your database
If we follow the example from above with 3 functions, then you have a control at which rate each thing happens really easily - no limit for reading from incoming queue, 10 for calling 3rd party API and 5 for inserting records to DB. And obviously you will need to monitor queues to understand where and if a bottleneck happens.
Another example, if there can be only single reader of huge file, you limit the parallelism to single instance of the reader, but the data processors may have infinite scale.
Summary
By following the rules above, I was able to deploy a large amount of Serverless applications and maintain it happily with other team mates. But the most important, that those rules prevented from me in some cases to use Serverless technology, as it was just not a good fit and probably would end up badly product and cost-wise.
Comments